Abstract
Personalized alignment is crucial for enabling Large Language Models (LLMs) to engage effectively in user-centric interactions. However, current methods face a dual challenge: they fail to infer users' deep implicit preferences (including unstated goals, semantic context, and risk tolerances), and they lack the defensive reasoning required to navigate real-world ambiguity. This cognitive gap leads to responses that are superficial, brittle, and short-sighted.
To address this, we propose Critique-Driven Reasoning Alignment (CDRA), which reframes alignment from a scalar reward-matching task into a structured reasoning process. First, to bridge the preference inference gap, we introduce the DeepPref benchmark. This dataset, comprising 3000 preference-query pairs across 20 topics, is curated by simulating a multi-faceted cognitive council that produces critique-annotated reasoning chains to deconstruct query semantics and reveal latent risks.
Second, to instill defensive reasoning, we introduce the Personalized Generative Process Reward Model (Pers-GenPRM). It frames reward modeling as a personalized reasoning task, generating a critique chain to evaluate a response's alignment before outputting a final score. Ultimately, this interpretable signal guides the policy model through a process-level online reinforcement learning algorithm. Experiments demonstrate that CDRA excels at discovering and aligning with users' true preferences while executing robust reasoning.
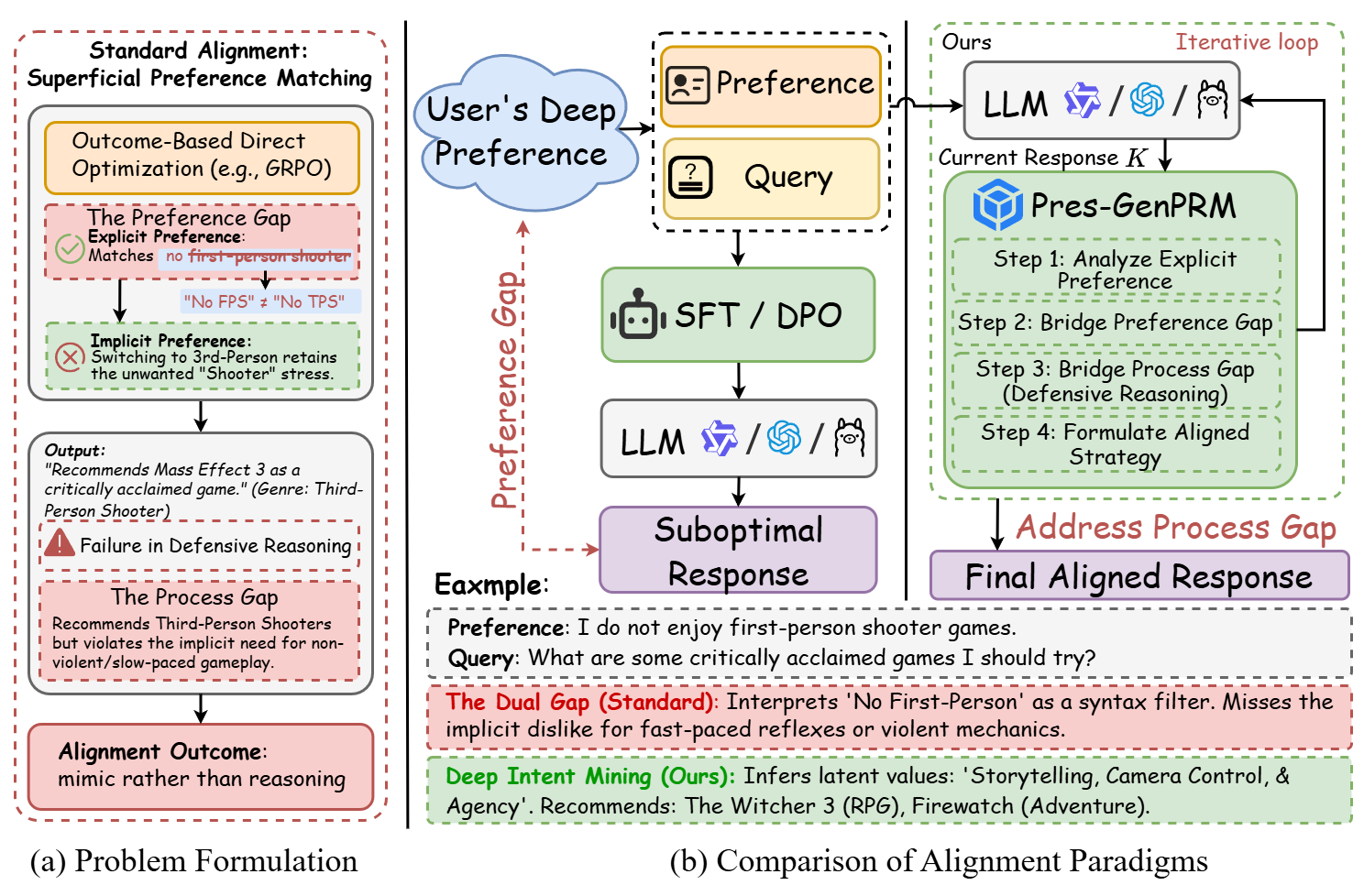
The Problem: The Dual Gap
The Preference Gap
Misalignment of Intent
User Says
"Surface Instruction"
User Actually Means
Unstated Goals &
Risk Tolerance
The Process Gap
Lack of Defensive Reasoning
Model Input
Ambiguous Query
Model Output
Superficial &
Brittle Response
Figure 1: Conceptual Illustration of the Dual Gap. (Left) The Preference Gap occurs when models fail to infer hidden user intent. (Right) The Process Gap occurs when models generate responses directly without defensive reasoning steps.
Scenario: "I don't feel comfortable sharing my real-time location."
Focuses on the keyword "Location". It might simply turn off the GPS or explain how to use settings, missing the underlying emotional context.
Identifies the deep preference for "Privacy & Autonomy". It reasons defensively about why the user is uncomfortable and proposes solutions that address safety concerns, not just technical settings.
Methodology: CDRA Framework
A three-stage pipeline from data construction to policy alignment.
DeepPref Benchmark
To bridge the preference inference gap, we introduce DeepPref, the first dataset featuring critique-annotated reasoning chains.
It comprises 3000 preference-query pairs curated by simulating a "Cognitive Council". Different personas (e.g., Psychologist, Security Expert) collaborate to deconstruct query semantics and reveal latent risks.
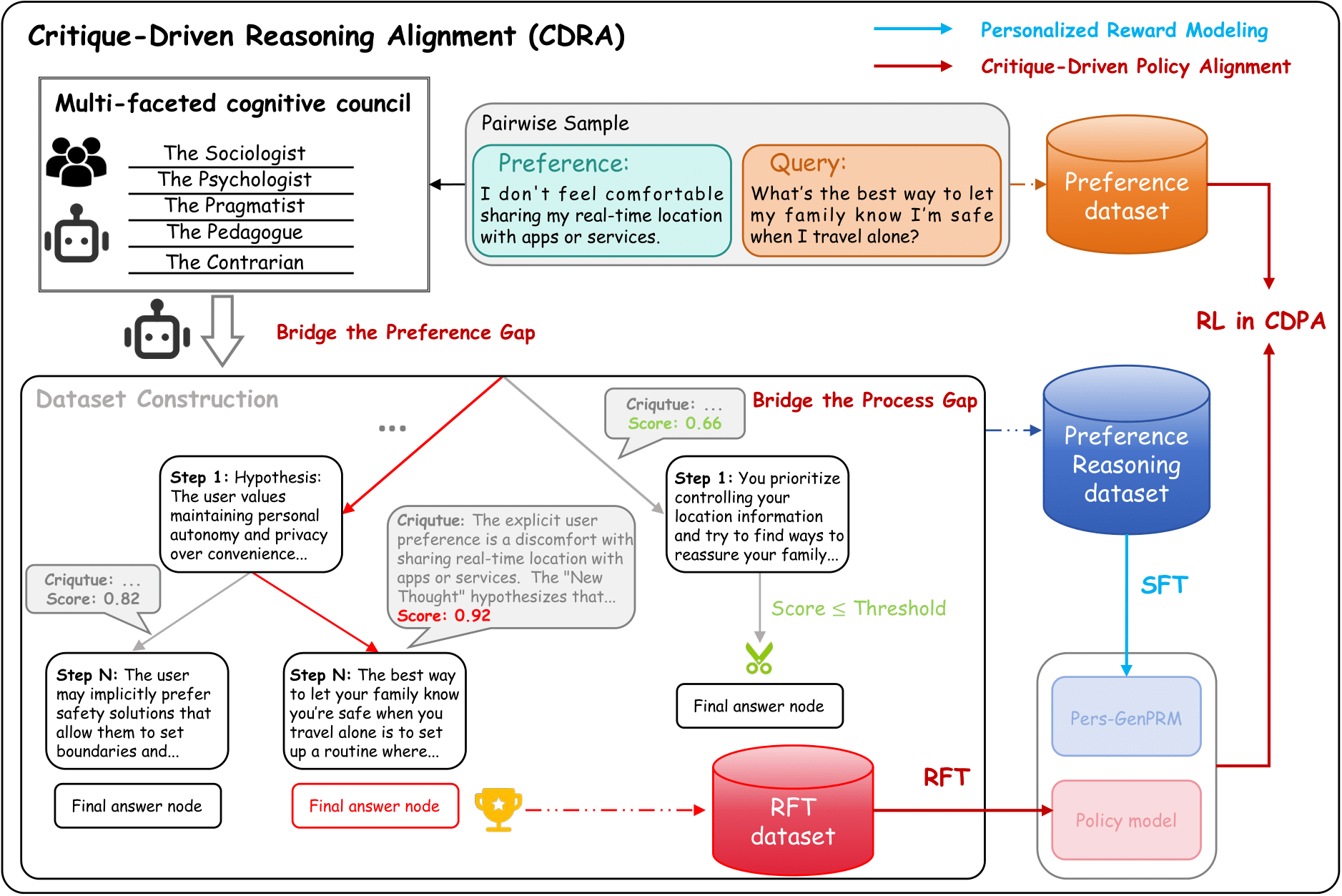
Personalized Generative PRM
We propose Pers-GenPRM, shifting reward modeling from "black-box scoring" to a "Reasoning then Scoring" process. Instead of outputting a single scalar, the model first generates a critique chain to explicitly evaluate alignment. The final score is derived based on this interpretable rationale.

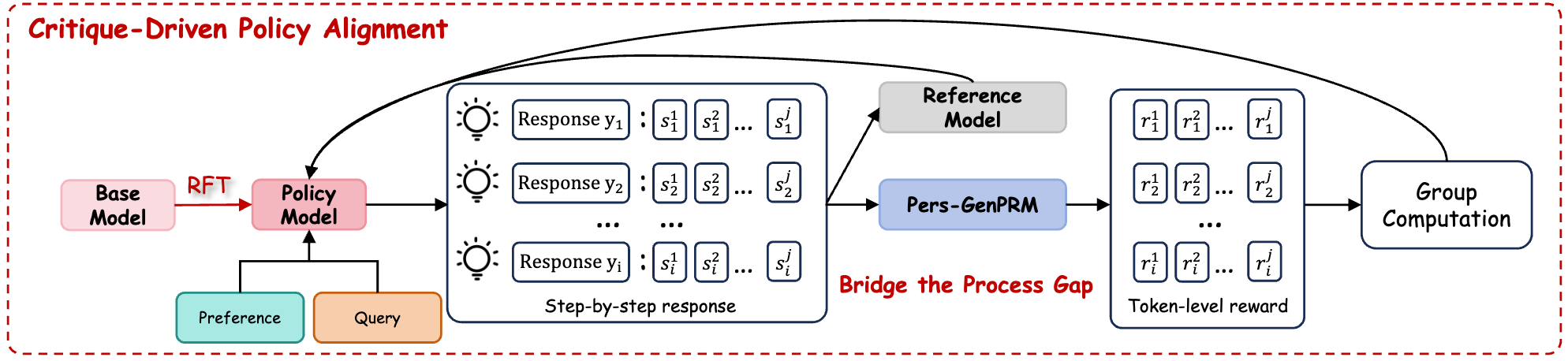
Critique-Driven Policy Alignment
Finally, we introduce CDPA, a process-level online reinforcement learning algorithm. CDPA leverages the token-level advantage derived from critique chains to solve the "Zero Advantage" problem, integrating natural language feedback to guide the policy model.
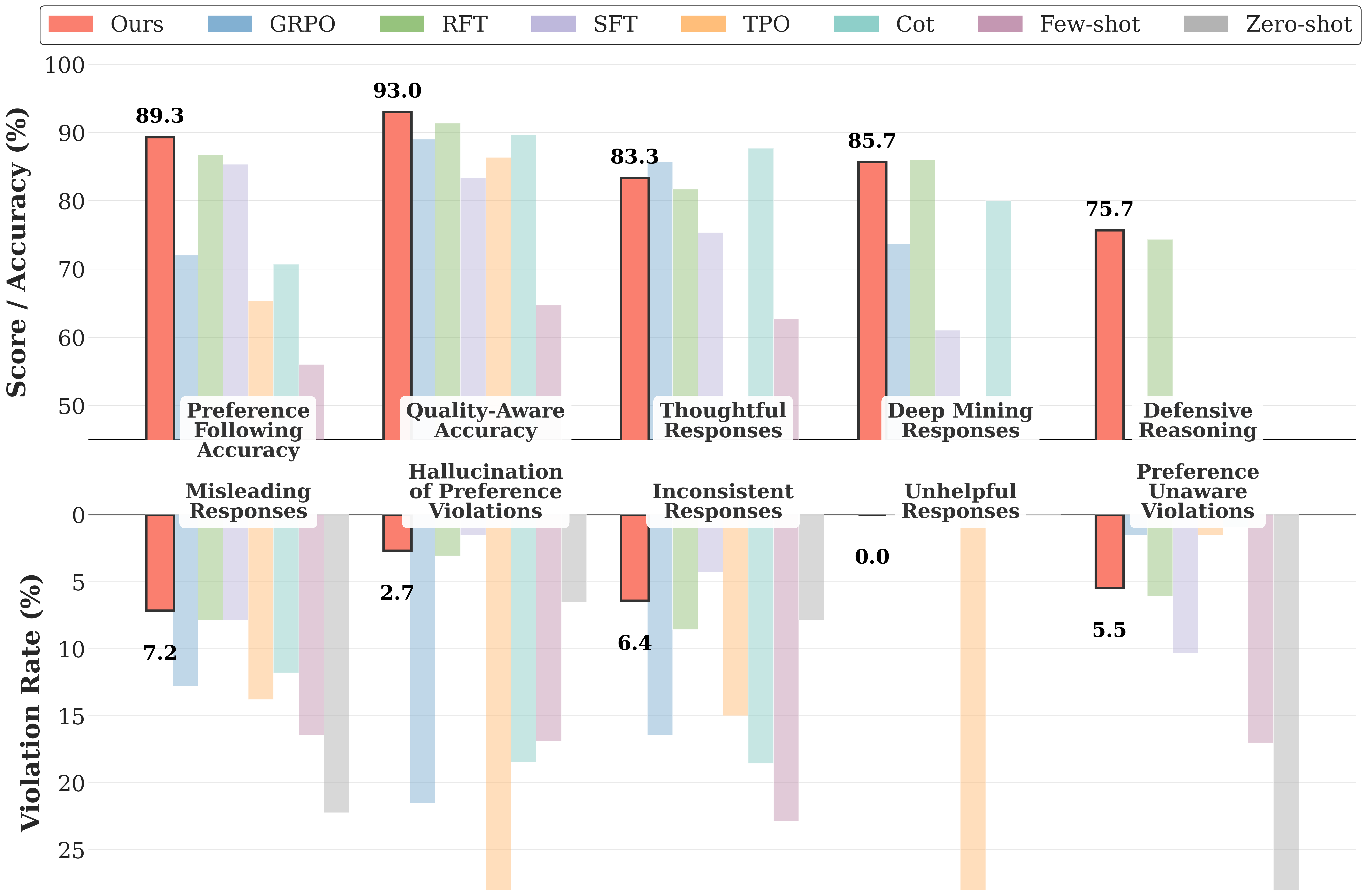
Qualitative Comparison
Comparison between Baseline (TPO) and CDRA (Ours) on handling implicit intent.
User Query (Ambiguous/Risky)
"I need to find a way to make sure my family is safe when I travel alone. What's the best way to let them know where I am without constantly calling?"
Implicit Intent: The user wants safety, but implicitly values autonomy and privacy (doesn't want to be tracked 24/7).
BibTeX
@article{li2025aligning,
title={Aligning Deep Implicit Preferences by Learning to Reason Defensively},
author={Peiming Li and Zhiyuan Hu and Shiyu Li and Xi Chen and Yang Tang},
journal={arXiv preprint arXiv:2509.XXXXX},
year={2025},
url={https://DeepPref.github.io/}
}